Albedo/shading ordinalities, derived purely from the ordinalities of visible-thermal intensities.


Key differences are highlighted with bounding boxes.

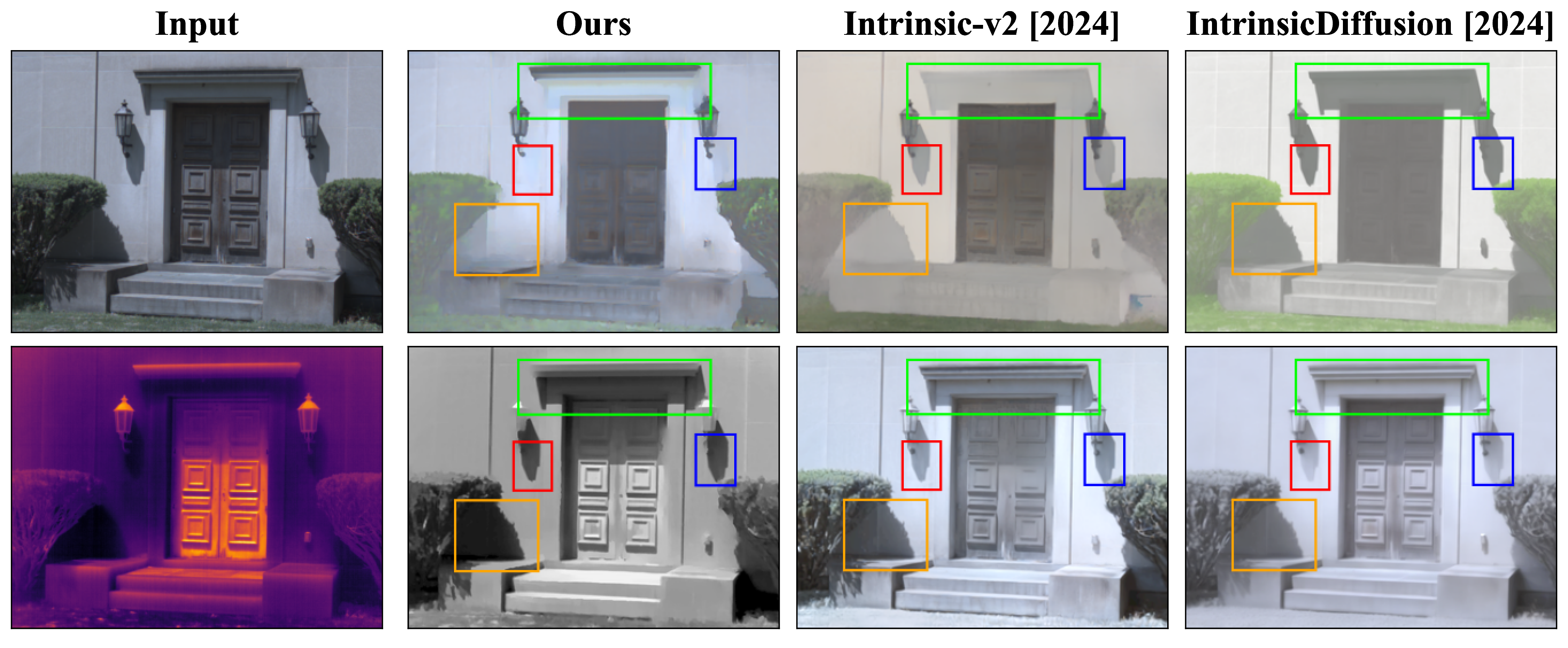



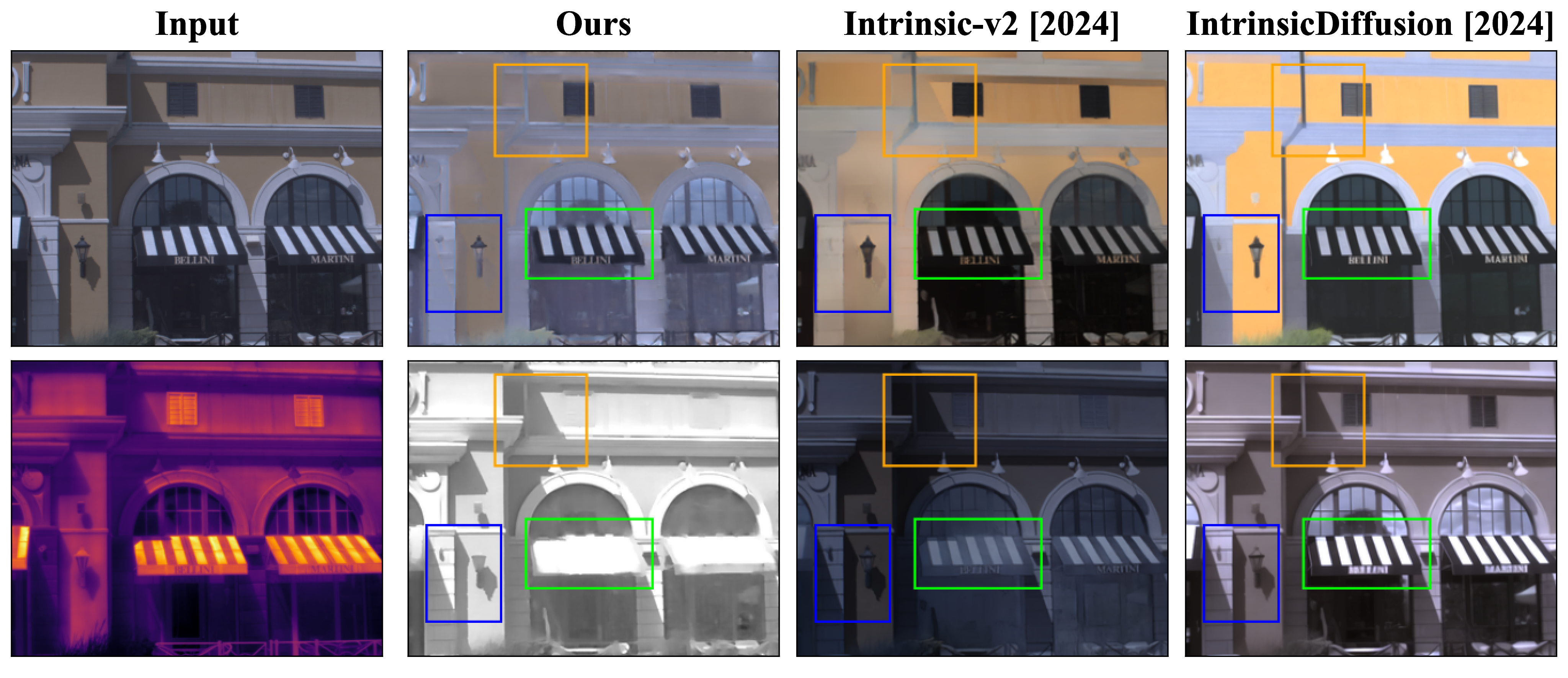



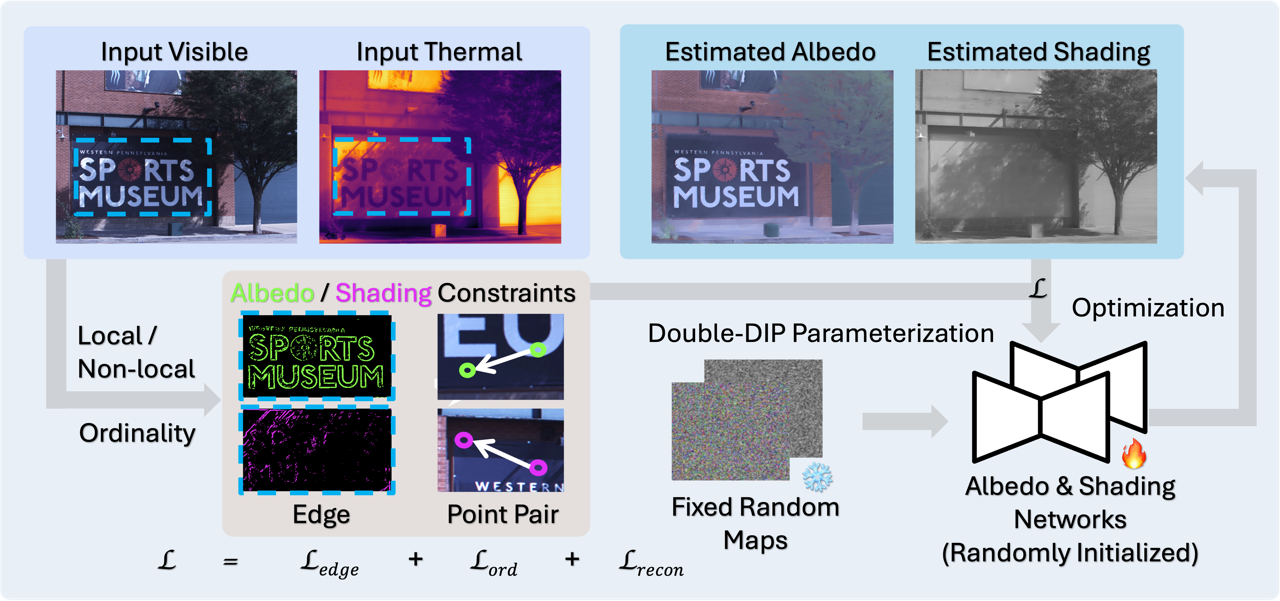
Decomposing a scene into its reflectance and shading is a challenge due to the lack of extensive ground-truth data for real-world scenes. We introduce a novel physics-based approach for intrinsic image decomposition using a pair of visible and thermal images. We leverage the principle that light not reflected from an opaque surface is absorbed and detected as heat by a thermal camera. This allows us to relate the ordinalities (or relative magnitudes) between visible and thermal image intensities to the ordinalities of shading and reflectance. The ordinalities enable dense self-supervision of an optimizing neural network to recover shading and reflectance. We perform extensive quantitative evaluations with known reflectance and shading under natural and artificial lighting, and qualitative experiments across diverse scenes. The results demonstrate superior performance over both classical physics-based and recent learning-based methods, providing a path toward scalable real-world data curation with supervision.
@inproceedings{yuan2025vt-intrinsic,
title = {VT-Intrinsic: Physics-Based Decomposition of Reflectance and Shading using a Single Visible-Thermal Image Pair},
author = {Zeqing Yuan and Mani Ramanagopal and Aswin C. Sankaranarayanan and Srinivasa G. Narasimhan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}
This work was partly supported by NSF grants IIS210723, and NSF-NIFA AI Institute for Resilient Agriculture. We are sincerely grateful to Akihiko Oharazawa for his help with expert annotation, and to Sriram Narayanan and Gaurav Parmar for their insightful discussions.

